Stop Burning Tokens on Subagents: A Model Routing Fix

You open Claude Code in the morning. By noon, you’re rate-limited. Sound familiar?
If you’re using workflows, skills, or the Agent tool heavily, the culprit is almost always model inheritance: every subagent you spawn defaults to whatever model your session is running — even when it’s doing something as simple as reading a file or checking a spec.
The fastest fix is tooling built for exactly this problem.
The Tools That Fix This
The AI landscape’s cost-reduction category collects tools built to cut token spend. Here’s how the five main ones compare — what each is best at, and what to watch for:
| Tool | Best at | Token reduction | Watch out for | Stars |
|---|---|---|---|---|
| Token Optimizer | All-round waste detection inside Claude Code — model routing, loop detection, conversation-history awareness | 99%+ per-output; real bill savings | PolyForm Noncommercial license; plugin install needed | ~1.3K |
| Headroom | Compressing everything agents read — tool output, logs, RAG, files | 60–95% | Adds processing overhead; can lose nuance | ~27K |
| RTK | Cutting token use on CLI/dev commands, near-zero overhead | 60–90% | Limited native Windows (use WSL) | ~62K |
| Context Mode | Sandboxing tool output across 16 platforms; persistent knowledge base | up to 98% on tool outputs | Adds an indirection layer; MCP required | ~17K |
| Claude Dashboard | Seeing where tokens go — local usage dashboard, burn-rate, heatmaps | Tracking only | New project; Claude Code logs only | ~9 |
Start here: Token Optimizer is the one that did this for us — it’s the only tool above that covers all the major waste sources (model routing, loop detection, and the conversation history that’s 60–75% of your bill), not just one. If your pain is specifically agents reading huge files, pair it with Headroom. And if you just want to see where your tokens go before changing anything, start with Claude Dashboard.
Why Subagents Are the Culprit
A Claude Code usage report from a heavy workflow user:
- 60% of usage came from subagent-heavy sessions
- 9% from
workflow-subagentalone — tasks like “explore the codebase” and “list markdown files” - 21% from a skills plugin that dispatched its own agents
The model those subagents were running on? opus[1m] — the most expensive tier with a 1M-context window. Set as the session default, every subagent inherited it automatically.
The fix wasn’t removing agents. It was routing them to the right model — which is exactly what Token Optimizer automates.
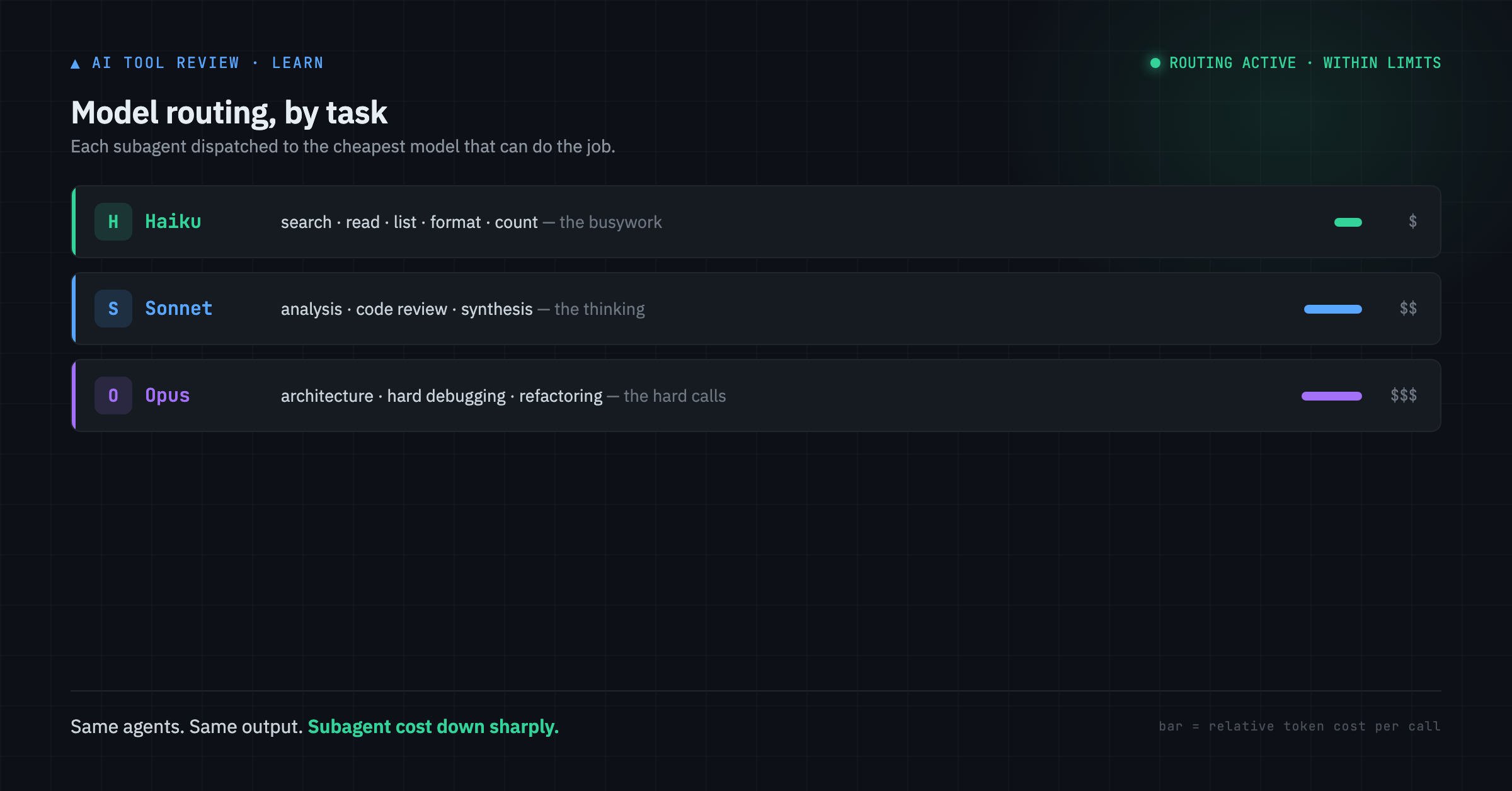 After: each subagent dispatched to the cheapest model that can do the job. Same agents, same output, far fewer tokens.
After: each subagent dispatched to the cheapest model that can do the job. Same agents, same output, far fewer tokens.
Related Resources
- Browse all cost-reduction tools → — the full category, including Token Optimizer, Headroom, RTK, Context Mode, and Claude Dashboard
- Managing AI Coding Tool Budgets — a broader look at keeping AI-assisted development affordable
- Loop Engineering — how to build agent loops that don’t run away with your budget
- Coding agents — compare Cline, Aider, GitHub Copilot, and other terminal/CLI agents